#collapse
import matplotlib.pyplot as plt
import numpy as np
import pickle
from pathlib import Path
import keras
def save_object(obj: object, file_path: Path) -> None:
"""
Save a python object to the disk and creates the file if does not exists already.
Args:
file_path - Path object for pkl file location
obj - object to be saved
Returns:
None
"""
if not file_path.exists():
file_path.touch()
print(f"pickle file {file_path.name} created successfully!")
else:
print(f"pickle file {file_path.name} already exists!")
with file_path.open(mode='wb') as file:
pickle.dump(obj, file, protocol=pickle.HIGHEST_PROTOCOL)
print(f"object {type(obj)} saved to file {file_path.name}!")
def load_object(file_path: Path) -> object:
"""
Loads the pickle object file from the disk.
Args:
file_path - Path object for pkl file location
Returns:
object
"""
if file_path.exists():
with file_path.open(mode='rb') as file:
print(f"loaded object from file {file_path.name}")
return pickle.load(file)
else:
raise FileNotFoundError
def vectorize_sequence(sequences: np.ndarray, dimension: int = 10000):
"""
Convert sequences into one-hot encoded matrix of dimension [len(sequence), dimension]
Args:
sequences - ndarray of shape [samples, words]
dimension = number of total words in vocab
Return:
vectorized sequence of shape [samples, one-hot-vecotor]
"""
# Create all-zero matrix
results = np.zeros((len(sequences), dimension))
for (i, sequence) in enumerate(sequences):
results[i, sequence] = 1.
return results
def plot_history(
history: keras.callbacks.History,
metric: str = 'acc',
save_path: Path = None,
model_name: str = None
) -> None:
"""
Plots the history of training of a model during epochs
Args: history:
model history - training history of a model
metric -
Plots:
1. Training and Validation Loss
2. Training and Validation Accuracy
"""
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
ax1.plot(history.epoch, history.history.get(
'loss'), "o", label='train loss')
ax1.plot(history.epoch, history.history.get(
'val_loss'), '-', label='val loss')
ax2.plot(history.epoch, history.history.get(
metric), 'o', label='train acc')
ax2.plot(history.epoch, history.history.get(
f"val_{metric}"), '-', label='val acc')
ax1.set_xlabel("epoch")
ax1.set_ylabel("loss")
ax2.set_xlabel("epoch")
ax2.set_ylabel("accuracy")
ax1.set_title("Loss")
ax2.set_title("Accuracy")
f.suptitle(f"Training History: {model_name}")
ax1.legend()
ax2.legend()
if save_path is not None:
f.savefig(save_path)Abstract
Authorship identification is the task of identifying the author of a given text from a set of suspects. The main concern of this task is to define an appropriate characterization of texts that captures the writing style of authors.
As a published author usually has a unique writing style in his/her work. The writing style is mostly context independent and is discernible by a human reader.
In previous studies various stylometric models have been suggested for the aforementioned task e.g. BiLSTM, SVM, Logistic Regression, several other Deep Learning Models. But most of them fail or show poor results for either short passages or long passages and none of them were able to perform well in both cases.
Previously the best performance at authroship identification is achieved by LSTM and GRU model.
Baseline Model
For setting up a baseline for the task, I used a combination of stack of 1D-CNN with BiLSTM which gives a validation accuracy: ~62% and test accuracy: ~54% while using a fairly simple BiDirectional LSTM and CNN Architecture. And unsurprisingly the results of baseline model are pretty close to the past best performing model without any type of Tuning.
Model uses pretrained GloVe word Embeddings for text representation. GloVe uncased word embeddings were trained using Wikipedia 2014 + Gigaword 5 and it consists of 6B tokens, 400K vocab. Embeddings are available as 50d, 100d, 200d, & 300d vectors. [Source]
In most of the cases training word embeddings for the downstream task is a good idea and gives better results, albeit because of computational requirements I have used pretrained GloVE embeddings.
Utilitiy functions
These are the functions that I’ll be using to do redundant tasks in this part like: 1. Plotting train history 2. Saving figures 3. Saving and Loading pickle objects
take a look if interested!
Structure of notebook
Data Preprocessing
Dataset: UCI C50 Dataset(small subset of origin RCV1 dataset) [Source] C50 dataset is widely used for authorship identification.
Dataset Specifications: >Catagories/Authors: 50
>Datapoints per class: 50
>Total Datapoints: 5000 (4500 train, 500 test)
Loading and Preprocessing the dataset
- 80-20 train and validation split and 500 holdout datapoints.
- I’ll use
text_dataset_from_directoryutility of keras library to load dataset which is faster than manually reading the text. - In the preprocessing step, numbers and special characters except
{.} {,} and {'}are removed from the dataset.
# collapse
# Import Python Regular Expression library
import re
src_dir = Path('data/C50_raw/')
src_test_dir = src_dir / 'test'
src_train_dir = src_dir / 'train'
dst_dir = Path('data/C50/')
dst_test_dir = dst_dir / 'test'
dst_train_dir = dst_dir / 'train'
test_sub_dirs = src_test_dir.iterdir()
train_sub_dirs = src_train_dir.iterdir()
for i, author in enumerate(test_sub_dirs):
author_name = author.name
dst_author = dst_test_dir / author_name
dst_author.mkdir()
for file in author.iterdir():
file_name = file.name
dst = dst_author / file_name
raw_text = file.read_text(encoding='utf-8')
out_text = re.sub("[^A-Za-z.',]+", " ", raw_text)
dst.write_text(out_text, encoding='utf-8')
for i, author in enumerate(train_sub_dirs):
author_name = author.name
dst_author = dst_train_dir / author_name
dst_author.mkdir()
for file in author.iterdir():
file_name = file.name
dst = dst_author / file_name
raw_text = file.read_text(encoding='utf-8')
out_text = re.sub("[^A-Za-z.',]+", " ", raw_text)
dst.write_text(out_text, encoding='utf-8')# collapse
nfiles_test = len(list(dst_test_dir.glob("*/*.txt")))
nfiles_train = len(list(dst_train_dir.glob("*/*.txt")))
print(f"Number of files in processed test dataset: {nfiles_test}")
print(f"Number of files in processed train dataset: {nfiles_train}")Number of files in processed test dataset: 500
Number of files in processed train dataset: 4500Load Dataset
#collapse
import keras
import numpy as np
import tensorflow as tf
from keras import models, layers
from keras.preprocessing import text_dataset_from_directory
from keras.layers.experimental.preprocessing import TextVectorization
import keras.callbacks as cb
ds_dir = Path('data/C50/')
train_dir = ds_dir / 'train'
test_dir = ds_dir / 'test'
seed = 123
batch_size = 32
train_ds = text_dataset_from_directory(
train_dir,
label_mode='categorical',
seed=seed,
shuffle=True,
batch_size=batch_size,
validation_split=0.2,
subset='training'
)
val_ds = text_dataset_from_directory(
train_dir,
label_mode='categorical',
seed=seed,
shuffle=True,
batch_size=batch_size,
validation_split=0.2,
subset='validation')
test_ds = text_dataset_from_directory(
test_dir,
label_mode='categorical',
seed=seed,
shuffle=True,
batch_size=batch_size)Found 4500 files belonging to 50 classes.
Using 3600 files for training.
Found 4500 files belonging to 50 classes.
Using 900 files for validation.
Found 500 files belonging to 50 classes.Inspect dataset
class_names = test_ds.class_names
class_names = np.asarray(class_names)
print(f"nclasses: {len(class_names)}")
print(f'first 4 classes/users: {class_names[:4]}')
for texts, labels in train_ds.take(1):
print("Shape of texts", texts.shape)
print(f'Class of 2nd data point: {class_names[labels.numpy()[1].astype(bool)]}')nclasses: 50
first 4 classes/users: ['AaronPressman' 'AlanCrosby' 'AlexanderSmith' 'BenjaminKangLim']
Shape of texts (32,)
Class of 2nd data point: ['GrahamEarnshaw']#collapse
MAX_LEN_TRAIN = 0
MAX_LEN_TEST = 0
for file in test_dir.glob('*/*.txt'):
with file.open() as f:
seq_len = 0
for line in f.readlines():
seq_len += len(line.split())
# print(seq_len)
if MAX_LEN_TEST < seq_len:
MAX_LEN_TEST = seq_len
for file in train_dir.glob('*/*.txt'):
with file.open() as f:
seq_len = 0
for line in f.readlines():
seq_len += len(line.split())
# print(seq_len)
if MAX_LEN_TRAIN < seq_len:
MAX_LEN_TRAIN = seq_len
print(f"length of largest article in train dataset: {MAX_LEN_TRAIN}")
print(f"length of largest article in test dataset: {MAX_LEN_TEST}")length of largest article in train dataset: 1498
length of largest article in test dataset: 1474#collapse
for batch, label in iter(val_ds):
index = np.argmax(label.numpy(), axis=1).astype(np.int)
print(f'Users of first batch: {class_names[index]}')
breakUsers of first batch: ['BradDorfman' 'JaneMacartney' 'RobinSidel' 'JanLopatka' 'GrahamEarnshaw'
'SamuelPerry' 'KouroshKarimkhany' "LynneO'Donnell" 'JaneMacartney'
'FumikoFujisaki' 'MarkBendeich' 'LynnleyBrowning' 'JanLopatka'
'EdnaFernandes' 'SimonCowell' 'KirstinRidley' 'MatthewBunce'
'MichaelConnor' 'KeithWeir' 'HeatherScoffield' 'MarcelMichelson'
'PatriciaCommins' 'MureDickie' 'TanEeLyn' 'MichaelConnor' 'MureDickie'
'MartinWolk' 'TanEeLyn' 'ScottHillis' 'KirstinRidley' 'ToddNissen'
'MichaelConnor']Text Vectorization
Text vectorization includes the following tasks using TextVectorization layer: 1. Standardization 2. Tokenization 3. Vectorization
Initial run of the vectorization layers
- Make a text-only dataset (without labels), then call adapt
- Do not call adapt on test dataset to prevent data-leak
- train and save vocab to disk
Note: Use it only for the first time or if vocab is not saved
#collapse
from utils import save_object
### Define vectorization layers
VOCAB_SIZE = 34000
MAX_LEN = 1450
vectorize_layer = TextVectorization(
max_tokens=VOCAB_SIZE,
output_mode='int',
output_sequence_length=MAX_LEN
)
# Train the layers to learn a vocab
train_text = train_ds.map(lambda text, lables: text)
vectorize_layer.adapt(train_text)
# Save the vocabulary to disk
# Run this cell for the first time only
vocab = vectorize_layer.get_vocabulary()
vocab_path = Path('vocab/vocab_C50.pkl')
save_object(vocab, vocab_path)
vocab_len = len(vocab)
print(f"vocab size of vectorizer: {vocab_len}")pickle file vocab_C50.pkl already exists!
object <class 'list'> saved to file vocab_C50.pkl!
vocab size of vectorizer: 34000Vectorization layers from saved vocab
Only run after first saving the vocabulary to the disk!
# collapse
# # Load vocab
# from utils import load_object
# vocab_path = Path('vocab/vocab_C50.pkl')
# vocab = load_object(vocab_path)
# VOCAB_SIZE = 34000
# MAX_LEN = 1500
# vectorize_layer = TextVectorization(
# max_tokens=VOCAB_SIZE,
# output_mode='int',
# output_sequence_length=MAX_LEN,
# vocabulary=vocab
# )Configure dataset
This is the final step of the data-processing pipeline where the text is converted into vectors, and then to train the model faster, dataset is prefetched and cached before each epoch. Prefetch is especially efficient when training on a GPU as the CPU fetch and cache the dataset while GPU is training in parallel and after finishing current epoch GPU doesn’t have to wait for CPU to load the data for next epoch.
def vectorize(text, label):
text = tf.expand_dims(text, -1)
return vectorize_layer(text), label
AUTOTUNE = tf.data.AUTOTUNE
def prepare(ds):
return ds.cache().prefetch(buffer_size=AUTOTUNE)
train_ds = train_ds.map(vectorize)
val_ds = val_ds.map(vectorize)
test_ds = test_ds.map(vectorize)
# Configure the datasets for fast training
train_ds = prepare(train_ds)
val_ds = prepare(val_ds)
test_ds = prepare(test_ds)Modelling
Now comes the most interesting part!
Below cell first creates an emb_index dictionary which maps words to a 100-Dimensional embedding vector and then emb_matrix is created which maps each word in C50 vocab to corresponding embedding.
##### Pretrained Glove Embeddings #####
## Parse the weights
from utils import load_object
emb_dim = 100
glove_file = Path(f'vocab/glove/glove.6B.{emb_dim}d.txt')
emb_index = {}
with glove_file.open(encoding='utf-8') as f:
for line in f.readlines():
values = line.split()
word = values[0]
coef = values[1:]
emb_index[word] = coef
##### Getting embedding weights #####
vocab = load_object(Path('vocab/vocab_C50.pkl'))
emb_matrix = np.zeros((VOCAB_SIZE, emb_dim))
for index, word in enumerate(vocab):
# get coef of word
emb_vector = emb_index.get(word)
if emb_vector is not None:
emb_matrix[index] = emb_vector
print(f"Embedding Dimensionality: {emb_matrix.shape}")loaded object from file vocab_C50.pkl
Embedding Dimensionality: (34000, 100)import keras.backend as K
from keras.utils import plot_model
from keras import regularizers
K.clear_session()
lstm_model = models.Sequential([
layers.Embedding(VOCAB_SIZE, emb_dim, input_shape=(MAX_LEN,)),
layers.SpatialDropout1D(0.3),
layers.Conv1D(256, 11, activation='relu'),
layers.MaxPooling1D(7),
layers.Dropout(0.4),
layers.BatchNormalization(),
layers.Bidirectional(layers.LSTM(128, return_sequences=True)),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Conv1D(128, 3, activation='relu'),
layers.MaxPooling1D(3),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Conv1D(64, 3, activation='relu'),
layers.GlobalMaxPooling1D(),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(128, activation='relu', kernel_regularizer=regularizers.l1_l2(l1=1e-5, l2=1e-4)),
layers.BatchNormalization(),
layers.Dense(50, activation='softmax')
])Detailed Architecture of the model
Load the emb_matrix as wieghts of the embedding layer of model and then set them as non-trainable.
lstm_model.layers[0].set_weights([emb_matrix])
lstm_model.layers[0].trainable = False
plot_model(lstm_model, show_layer_names=False, show_shapes=True, to_file="models/base.png")
Training the model
# from keras.optimizers import RMSprop
K.clear_session()
# optim = RMSprop(lr=1e-2)
################# Configure Callbacks #################
# Early Stopping
es = cb.EarlyStopping(
monitor='val_loss',
min_delta=5e-4,
patience=5,
verbose=1,
mode='auto',
restore_best_weights=True
)
# ReduceLROnPlateau
reduce_lr = cb.ReduceLROnPlateau(
monitor='val_loss',
factor=0.4,
patience=3,
verbose=1,
mode='auto',
min_delta=5e-3,
min_lr=1e-6
)
# Tensorboard
tb = cb.TensorBoard(
log_dir="./logs",
write_graph=True,
)
################# Model Training #################
lstm_model.compile(
loss='CategoricalCrossentropy',
optimizer='adam',
metrics=['acc']
)
lstm_history = lstm_model.fit(
train_ds,
validation_data=val_ds,
epochs=100,
callbacks=[es, reduce_lr, tb]
)
lstm_model.save('models/base.h5')Epoch 1/100
113/113 [==============================] - 35s 220ms/step - loss: 4.5336 - acc: 0.0188 - val_loss: 3.9713 - val_acc: 0.0200
Epoch 2/100
113/113 [==============================] - 13s 114ms/step - loss: 4.2080 - acc: 0.0312 - val_loss: 3.8599 - val_acc: 0.0278
Epoch 3/100
113/113 [==============================] - 13s 116ms/step - loss: 3.8997 - acc: 0.0403 - val_loss: 3.5842 - val_acc: 0.0544
Epoch 4/100
113/113 [==============================] - 13s 118ms/step - loss: 3.6826 - acc: 0.0454 - val_loss: 3.4762 - val_acc: 0.0467
Epoch 5/100
113/113 [==============================] - 13s 118ms/step - loss: 3.4679 - acc: 0.0585 - val_loss: 3.2102 - val_acc: 0.0900
Epoch 6/100
113/113 [==============================] - 13s 119ms/step - loss: 3.2866 - acc: 0.0862 - val_loss: 3.1259 - val_acc: 0.0844
Epoch 7/100
113/113 [==============================] - 13s 119ms/step - loss: 3.1113 - acc: 0.0972 - val_loss: 2.9419 - val_acc: 0.1533
Epoch 8/100
113/113 [==============================] - 17s 153ms/step - loss: 2.9159 - acc: 0.1459 - val_loss: 2.9488 - val_acc: 0.1456
Epoch 9/100
113/113 [==============================] - 17s 153ms/step - loss: 2.7023 - acc: 0.1737 - val_loss: 2.8818 - val_acc: 0.1544
Epoch 10/100
113/113 [==============================] - 17s 151ms/step - loss: 2.4595 - acc: 0.2387 - val_loss: 2.2731 - val_acc: 0.2889
Epoch 11/100
113/113 [==============================] - 17s 153ms/step - loss: 2.3077 - acc: 0.2764 - val_loss: 2.0811 - val_acc: 0.3033
Epoch 12/100
113/113 [==============================] - 17s 154ms/step - loss: 2.1691 - acc: 0.3154 - val_loss: 2.2417 - val_acc: 0.2622
Epoch 13/100
113/113 [==============================] - 18s 156ms/step - loss: 2.0237 - acc: 0.3493 - val_loss: 2.1130 - val_acc: 0.3178
Epoch 14/100
113/113 [==============================] - 17s 152ms/step - loss: 1.9448 - acc: 0.3544 - val_loss: 1.8156 - val_acc: 0.4133
Epoch 15/100
113/113 [==============================] - 17s 154ms/step - loss: 1.8491 - acc: 0.3828 - val_loss: 1.8381 - val_acc: 0.3789
Epoch 16/100
113/113 [==============================] - 17s 150ms/step - loss: 1.7508 - acc: 0.3922 - val_loss: 1.8668 - val_acc: 0.3789
Epoch 17/100
113/113 [==============================] - 18s 156ms/step - loss: 1.6681 - acc: 0.4339 - val_loss: 1.7776 - val_acc: 0.4022
Epoch 18/100
113/113 [==============================] - 17s 153ms/step - loss: 1.6276 - acc: 0.4328 - val_loss: 1.6306 - val_acc: 0.4411
Epoch 19/100
113/113 [==============================] - 17s 154ms/step - loss: 1.5808 - acc: 0.4466 - val_loss: 1.6069 - val_acc: 0.4522
Epoch 20/100
113/113 [==============================] - 17s 155ms/step - loss: 1.4749 - acc: 0.4696 - val_loss: 1.7228 - val_acc: 0.4089
Epoch 21/100
113/113 [==============================] - 17s 152ms/step - loss: 1.4379 - acc: 0.4849 - val_loss: 1.5438 - val_acc: 0.4567
Epoch 22/100
113/113 [==============================] - 17s 150ms/step - loss: 1.4126 - acc: 0.4781 - val_loss: 1.5012 - val_acc: 0.4667
Epoch 23/100
113/113 [==============================] - 17s 153ms/step - loss: 1.3508 - acc: 0.5022 - val_loss: 1.5094 - val_acc: 0.4467
Epoch 24/100
113/113 [==============================] - 17s 152ms/step - loss: 1.3220 - acc: 0.5124 - val_loss: 1.3901 - val_acc: 0.5067
Epoch 25/100
113/113 [==============================] - 17s 151ms/step - loss: 1.2896 - acc: 0.5279 - val_loss: 1.3944 - val_acc: 0.5056
Epoch 26/100
113/113 [==============================] - 17s 153ms/step - loss: 1.2639 - acc: 0.5314 - val_loss: 1.3389 - val_acc: 0.5244
Epoch 27/100
113/113 [==============================] - 17s 155ms/step - loss: 1.2449 - acc: 0.5533 - val_loss: 1.4641 - val_acc: 0.5044
Epoch 28/100
113/113 [==============================] - 17s 154ms/step - loss: 1.2253 - acc: 0.5574 - val_loss: 1.2490 - val_acc: 0.5756
Epoch 29/100
113/113 [==============================] - 17s 153ms/step - loss: 1.1860 - acc: 0.5534 - val_loss: 1.2377 - val_acc: 0.5744
Epoch 30/100
113/113 [==============================] - 17s 153ms/step - loss: 1.1334 - acc: 0.5763 - val_loss: 1.3690 - val_acc: 0.5100
Epoch 31/100
113/113 [==============================] - 17s 154ms/step - loss: 1.1058 - acc: 0.5856 - val_loss: 1.3175 - val_acc: 0.5678
Epoch 32/100
113/113 [==============================] - 17s 152ms/step - loss: 1.0955 - acc: 0.5932 - val_loss: 1.2472 - val_acc: 0.5667
Epoch 00032: ReduceLROnPlateau reducing learning rate to 0.0004000000189989805.
Epoch 33/100
113/113 [==============================] - 17s 151ms/step - loss: 1.0554 - acc: 0.6074 - val_loss: 1.2565 - val_acc: 0.5433
Epoch 34/100
113/113 [==============================] - 17s 153ms/step - loss: 1.0444 - acc: 0.6218 - val_loss: 1.2164 - val_acc: 0.5711
Epoch 35/100
113/113 [==============================] - 17s 154ms/step - loss: 0.9743 - acc: 0.6205 - val_loss: 1.1523 - val_acc: 0.5956
Epoch 36/100
113/113 [==============================] - 17s 150ms/step - loss: 0.9554 - acc: 0.6343 - val_loss: 1.2389 - val_acc: 0.5656
Epoch 37/100
113/113 [==============================] - 18s 157ms/step - loss: 0.9462 - acc: 0.6412 - val_loss: 1.1904 - val_acc: 0.5767
Epoch 38/100
113/113 [==============================] - 18s 163ms/step - loss: 0.9341 - acc: 0.6527 - val_loss: 1.1958 - val_acc: 0.5922
Epoch 00038: ReduceLROnPlateau reducing learning rate to 0.00016000000759959222.
Epoch 39/100
113/113 [==============================] - 18s 156ms/step - loss: 0.8854 - acc: 0.6792 - val_loss: 1.1309 - val_acc: 0.6078
Epoch 40/100
113/113 [==============================] - 17s 153ms/step - loss: 0.8495 - acc: 0.6747 - val_loss: 1.1413 - val_acc: 0.6022
Epoch 41/100
113/113 [==============================] - 18s 157ms/step - loss: 0.8854 - acc: 0.6635 - val_loss: 1.1481 - val_acc: 0.6044
Epoch 42/100
113/113 [==============================] - 17s 154ms/step - loss: 0.8528 - acc: 0.6802 - val_loss: 1.1488 - val_acc: 0.5967
Epoch 00042: ReduceLROnPlateau reducing learning rate to 6.40000042039901e-05.
Epoch 43/100
113/113 [==============================] - 18s 155ms/step - loss: 0.8528 - acc: 0.6895 - val_loss: 1.1268 - val_acc: 0.6056
Epoch 44/100
113/113 [==============================] - 17s 154ms/step - loss: 0.8339 - acc: 0.6923 - val_loss: 1.1091 - val_acc: 0.6167
Epoch 45/100
113/113 [==============================] - 18s 156ms/step - loss: 0.8147 - acc: 0.6870 - val_loss: 1.1009 - val_acc: 0.6122
Epoch 46/100
113/113 [==============================] - 17s 153ms/step - loss: 0.8440 - acc: 0.6834 - val_loss: 1.1055 - val_acc: 0.6167
Epoch 47/100
113/113 [==============================] - 18s 157ms/step - loss: 0.8263 - acc: 0.6752 - val_loss: 1.1083 - val_acc: 0.6122
Epoch 48/100
113/113 [==============================] - 18s 158ms/step - loss: 0.7950 - acc: 0.7115 - val_loss: 1.1292 - val_acc: 0.6078
Epoch 00048: ReduceLROnPlateau reducing learning rate to 2.560000284574926e-05.
Epoch 49/100
113/113 [==============================] - 18s 157ms/step - loss: 0.8392 - acc: 0.6807 - val_loss: 1.1152 - val_acc: 0.6133
Epoch 50/100
113/113 [==============================] - 17s 154ms/step - loss: 0.8248 - acc: 0.7110 - val_loss: 1.1076 - val_acc: 0.6167
Restoring model weights from the end of the best epoch.
Epoch 00050: early stopping# Model evaluation
print('Model evaluation on test dataset')
lstm_model.evaluate(test_ds)
# Plot training history
plot_history(
lstm_history,
model_name="ConvnetBiLSTM",
save_path=Path('plots/base.jpg')
)Model evaluation on test dataset
16/16 [==============================] - 1s 58ms/step - loss: 1.4009 - acc: 0.5360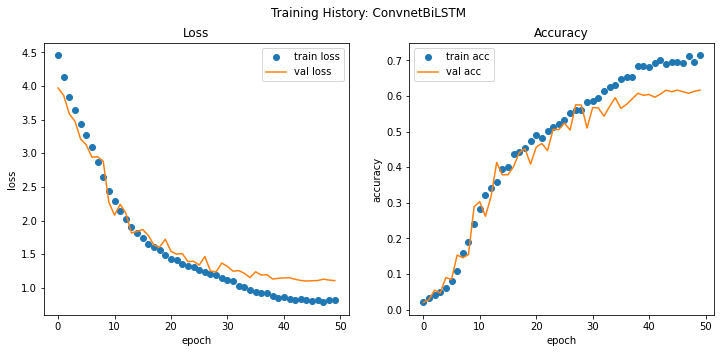
Summary
The simple BiLSTM + Conv1D model performs fairly well considering that it was not tuned for performance and provides a good baseline to work with. A clear thing to note here is that, While performance of the model on validation dataset is quite good but it performs poorly on the test. Model doesn’t generalize well on the holdout dataset which is our primary goal, in the text part I’ll try to improve the accuracy to make it better than the baseline.